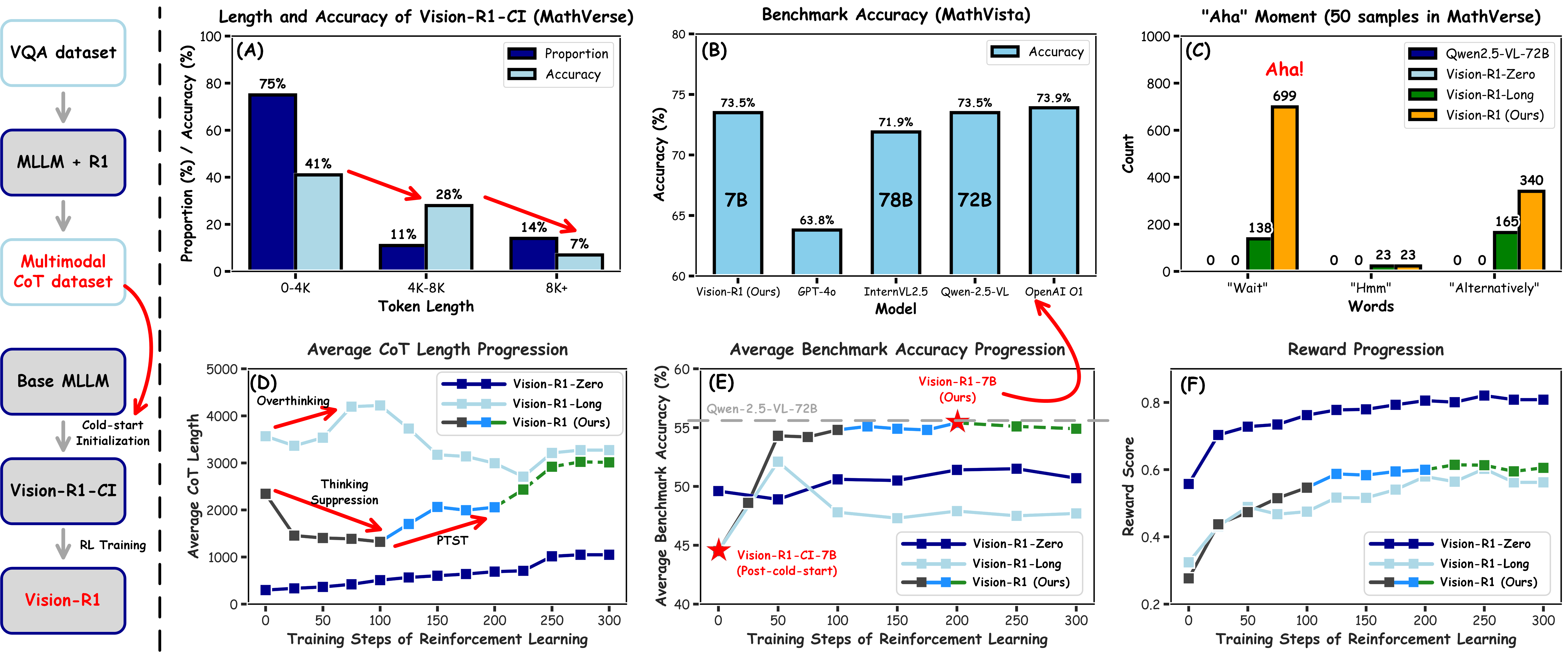
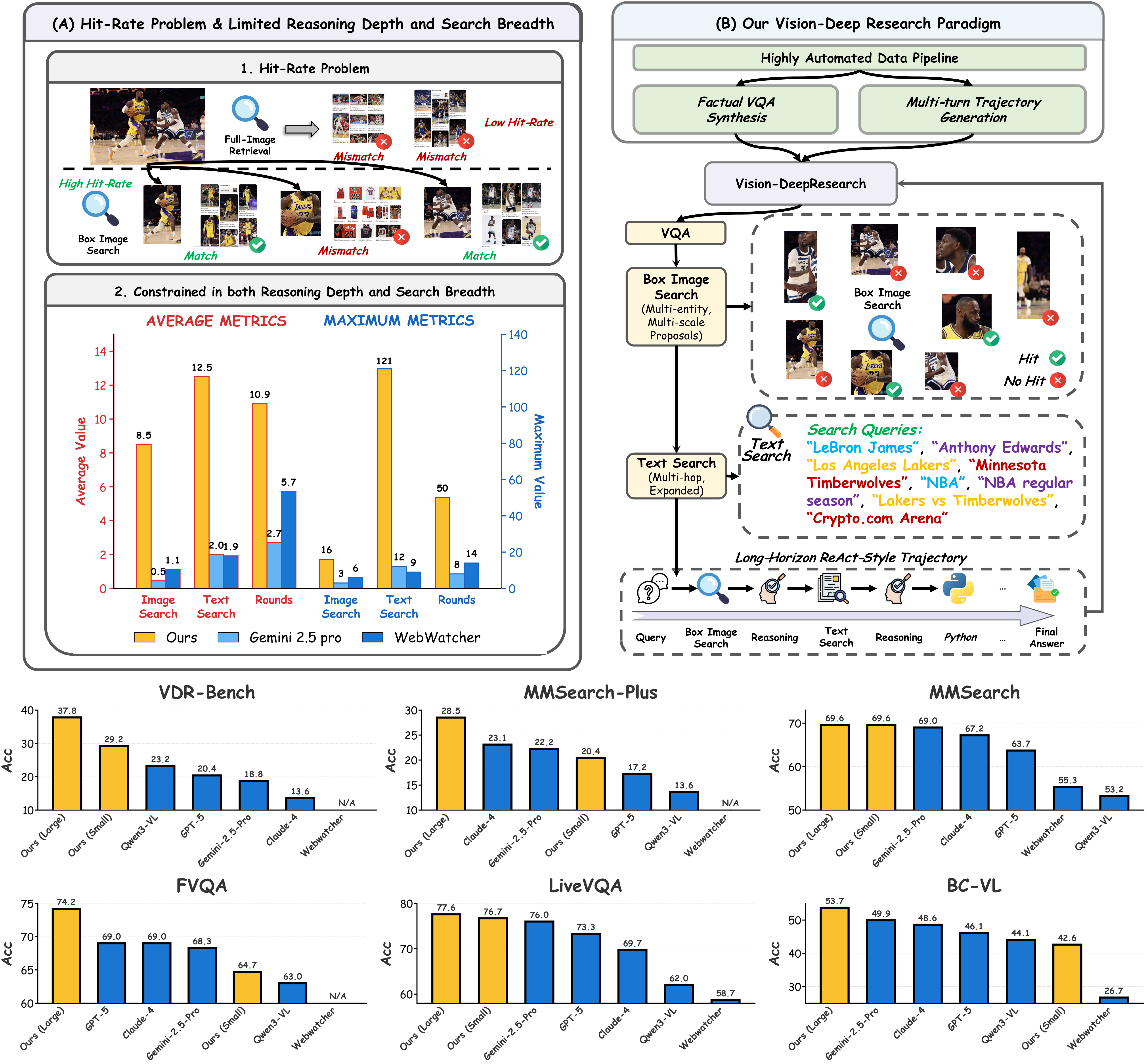
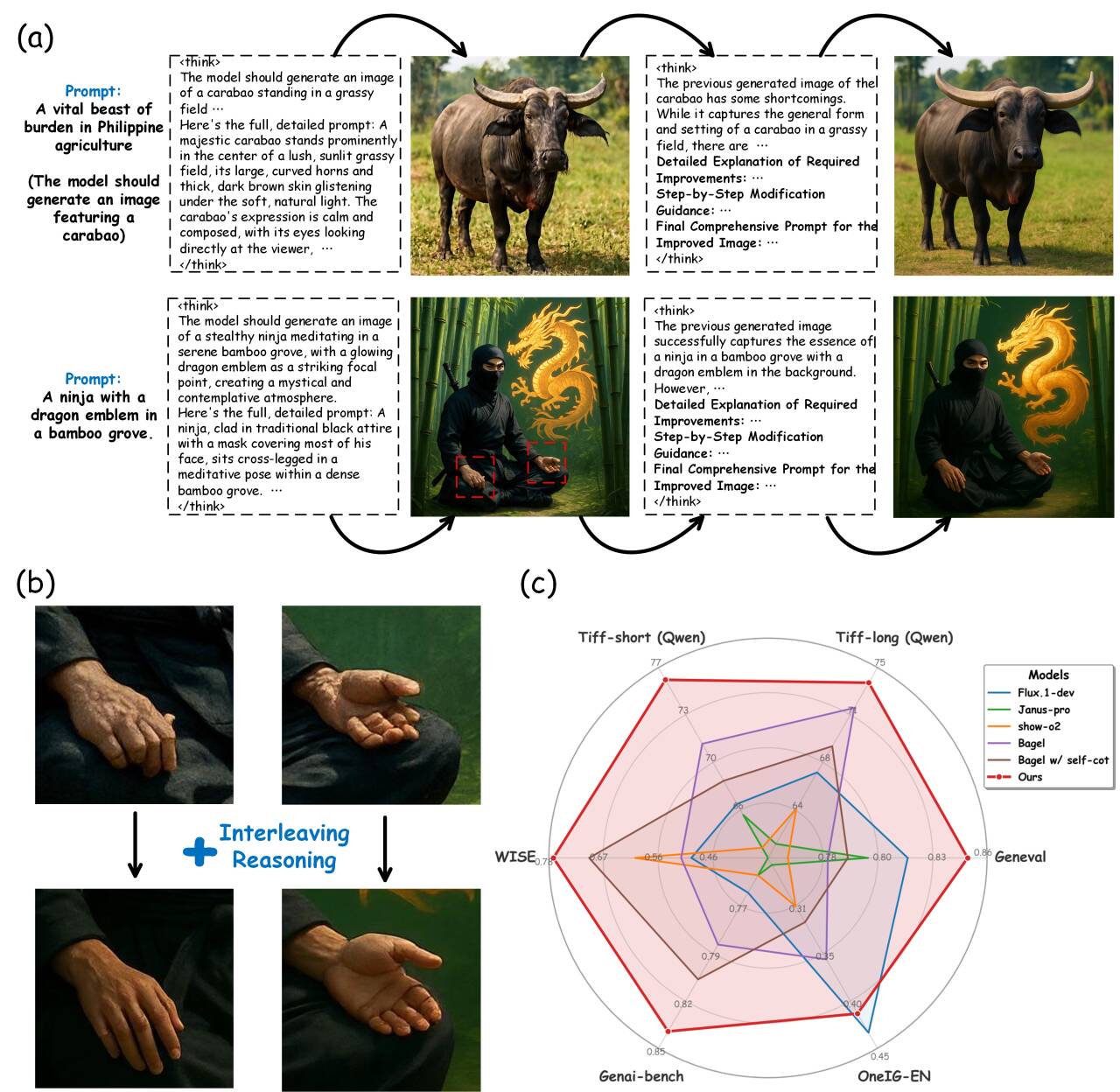
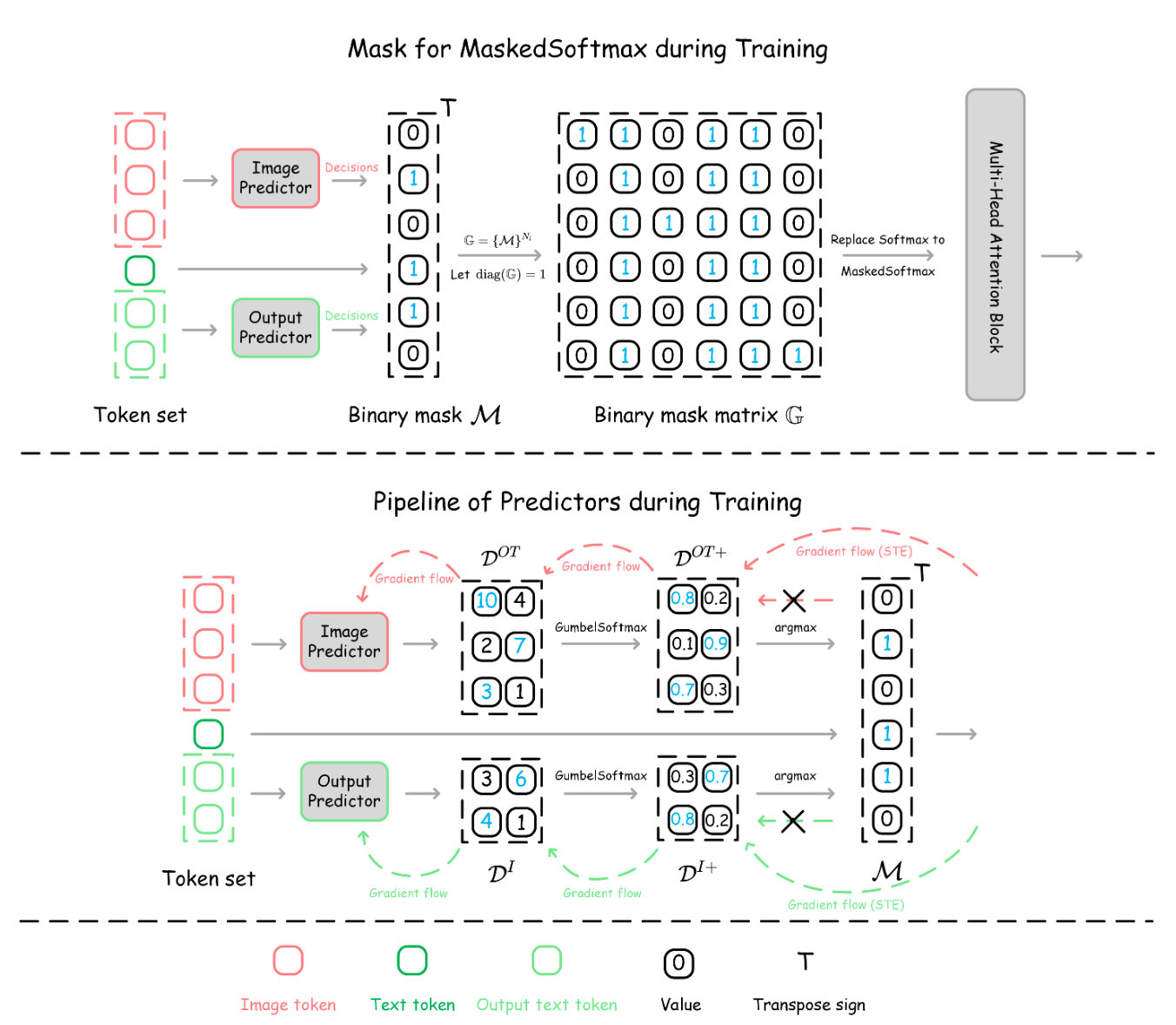
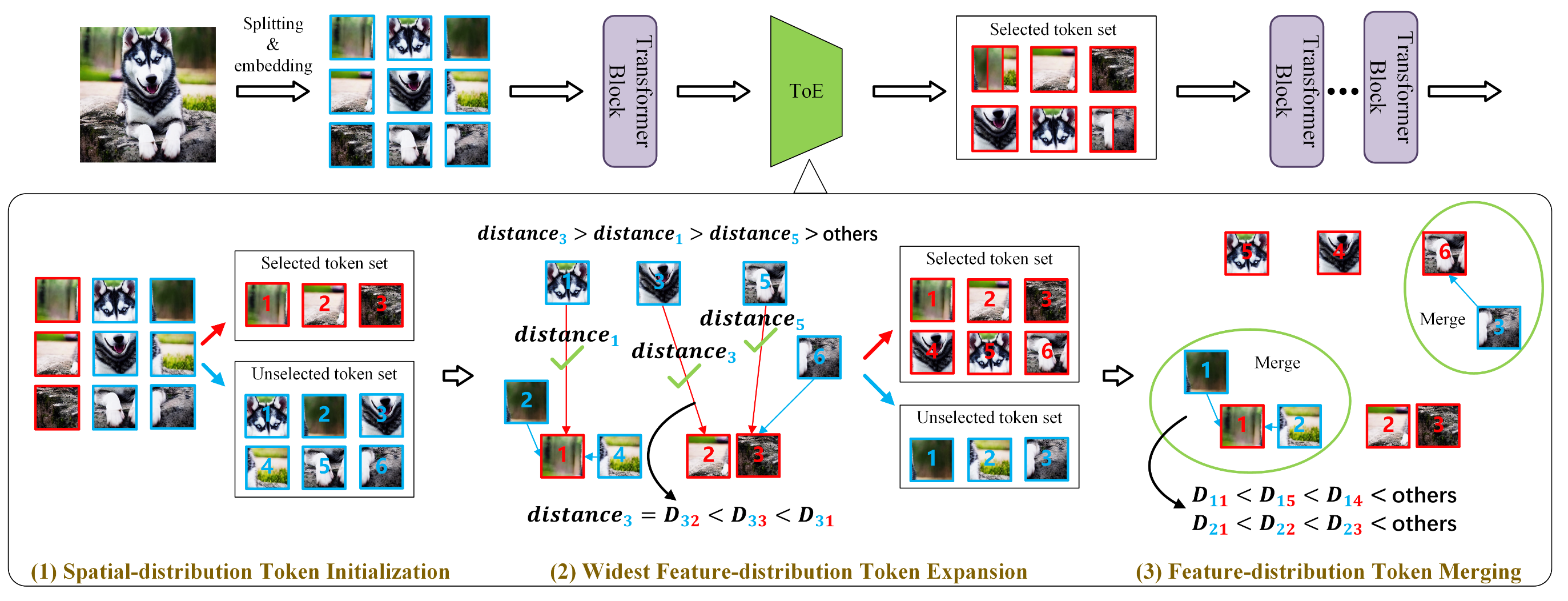
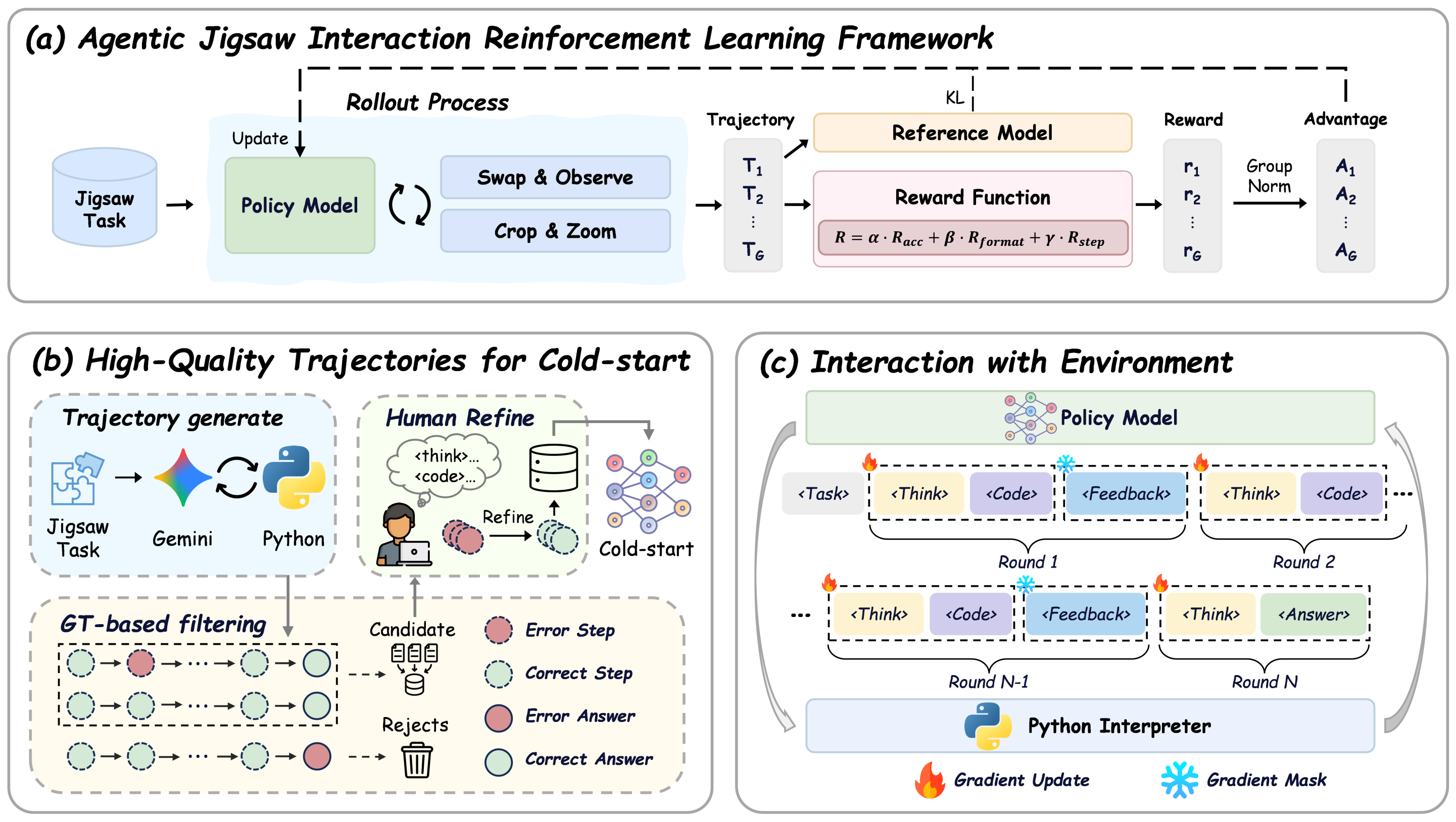
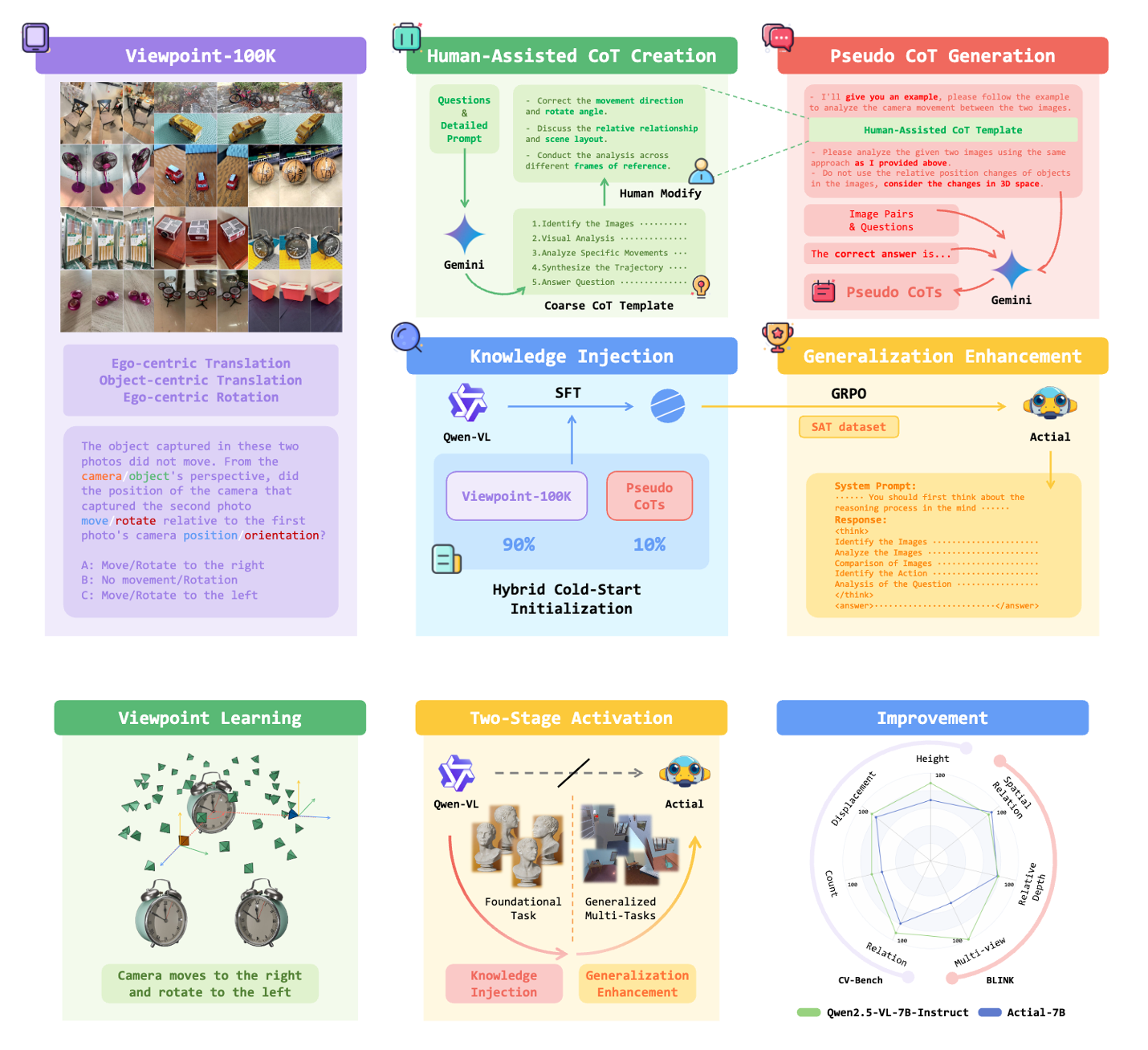
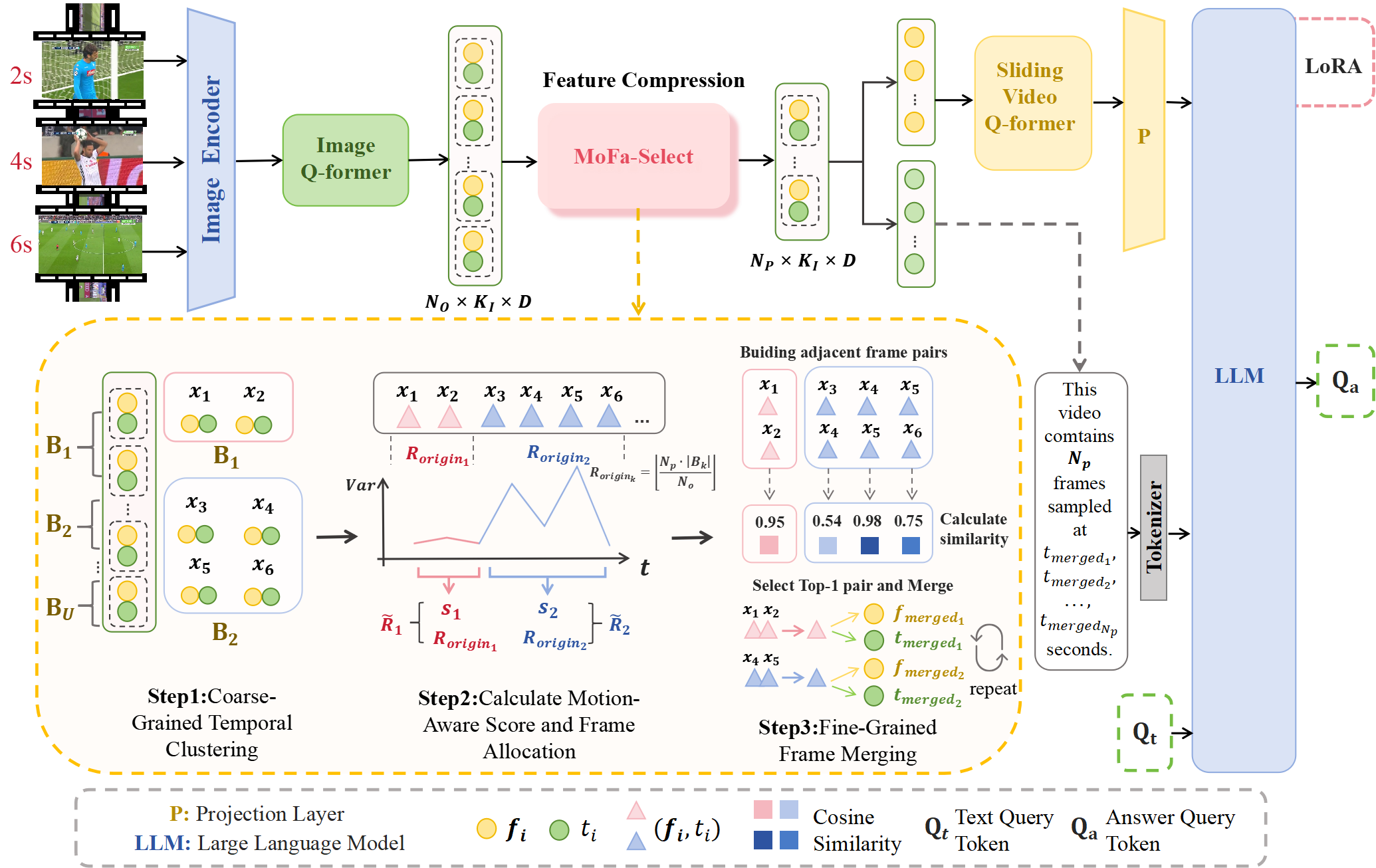
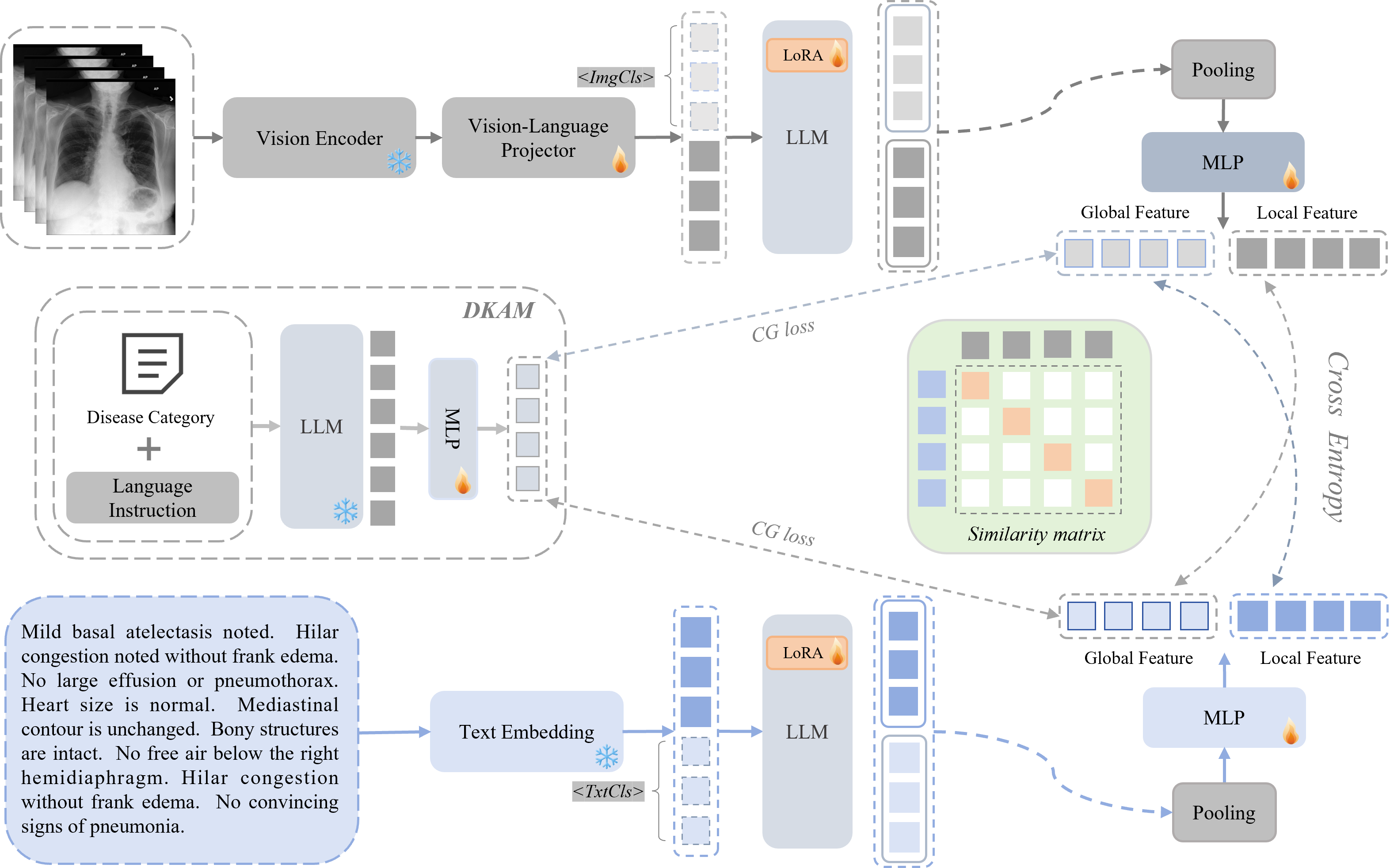
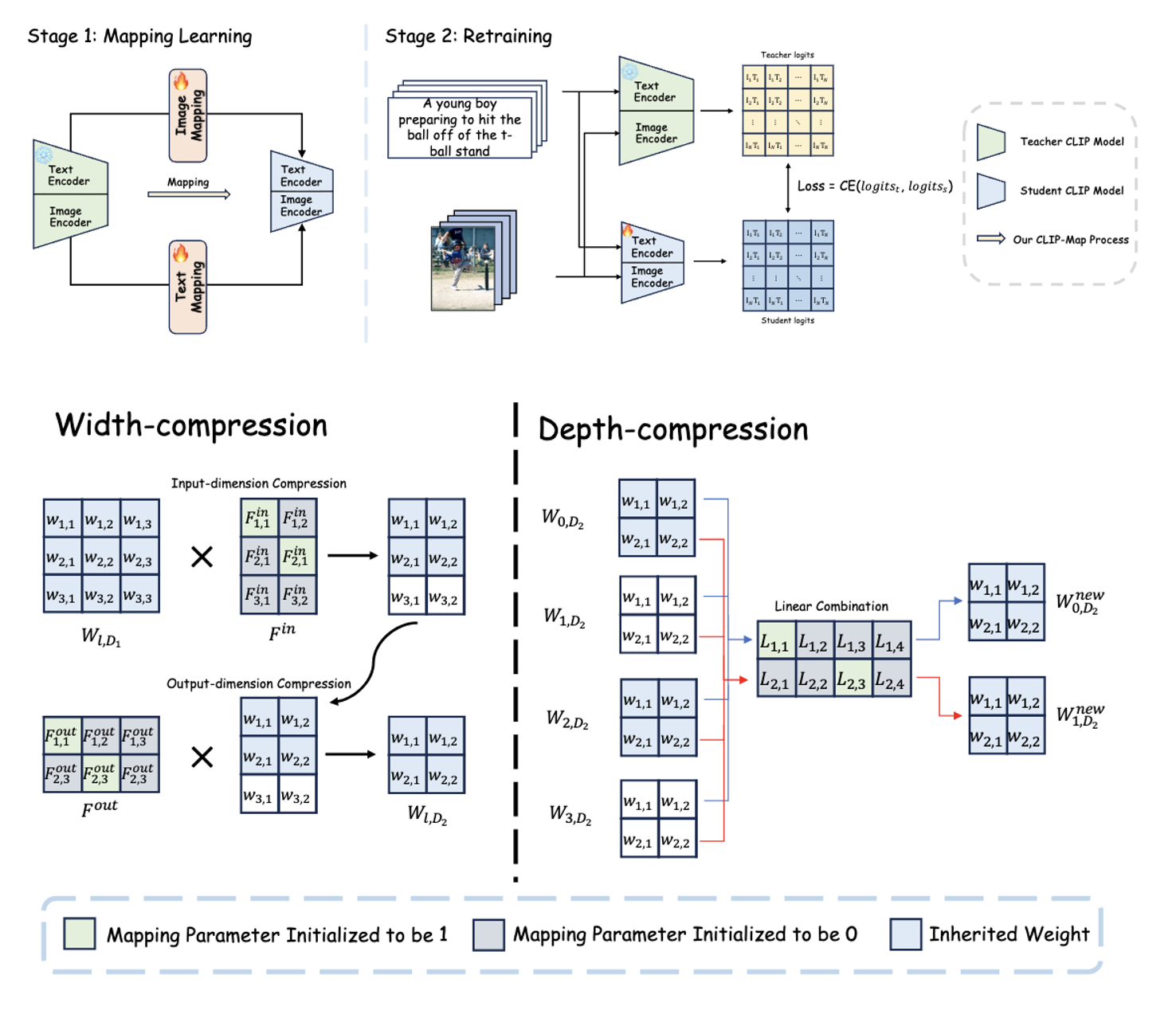
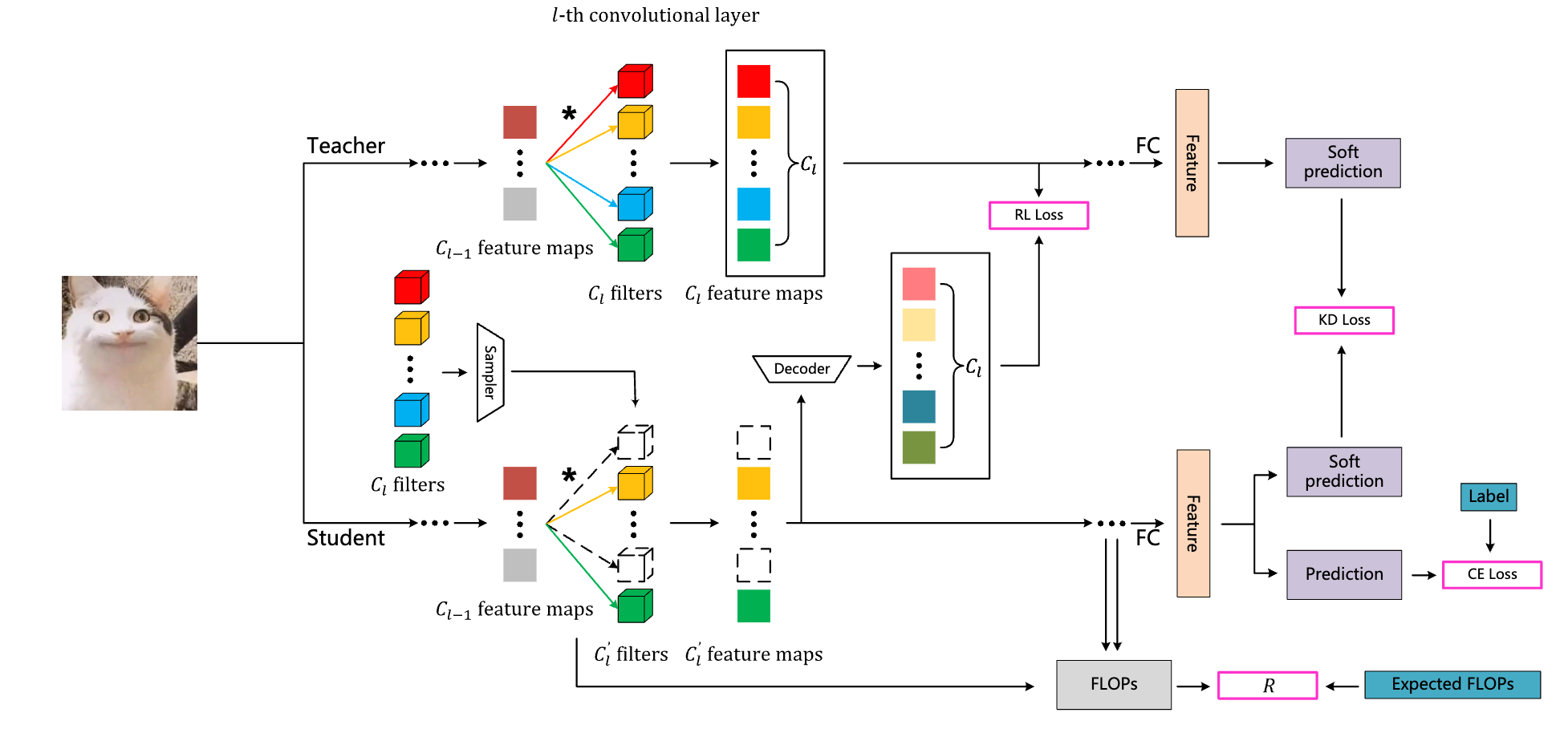
")
Wenxuan Huang (黄文轩)
![]()


Master in East China Normal
University
Personal Email : osilly0616 (at) gmail.com